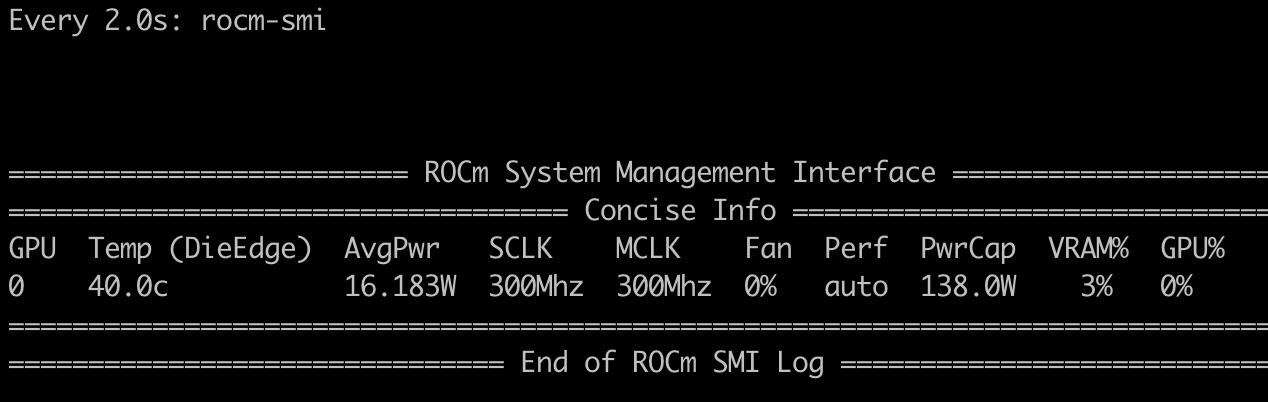
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
(venv) tiny@box:~/tinygrad$ JIT=1 GPU=1 python3 examples/llama.py --gen="tiny" --size="1B" --model="weights/LLaMA-tiny/model.safetensors" --temperature=0.2 --count=120 --prompt="best way to learn golang is "
using GPU backend
=== MODEL_PATH weights/LLaMA-tiny/model.safetensors
=== TOKENIZER_PATH weights/LLaMA-tiny/tokenizer.model
using LLaMA-tiny-1B model
ram used: 4.40 GB, freqs_cis : 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 202/202 [00:01<00:00, 111.45it/s]
loaded weights in 1816.11 ms, 4.40 GB loaded at 2.42 GB/s
best way to learn golang is Traceback (most recent call last):
File "examples/llama.py", line 419, in <module>
tok = llama.model(Tensor([toks[start_pos:]]), start_pos, args.temperature).item()
File "/home/tiny/tinygrad/extra/models/llama.py", line 153, in __call__
return self.forward(tokens, start_pos, temperature)
File "/home/tiny/tinygrad/extra/models/llama.py", line 140, in forward
for layer in self.layers: h = layer(h, start_pos, freqs_cis, mask)
File "/home/tiny/tinygrad/extra/models/llama.py", line 121, in __call__
h = x + self.attention(self.attention_norm(x), start_pos, freqs_cis, mask)
File "/home/tiny/tinygrad/extra/models/llama.py", line 92, in __call__
self.cache_k.assign(keys.pad((None,(0,self.max_context-start_pos-seqlen),None,None)).contiguous()).realize()
File "/home/tiny/tinygrad/tinygrad/tensor.py", line 113, in realize
run_schedule(self.lazydata.schedule())
File "/home/tiny/tinygrad/tinygrad/realize.py", line 31, in run_schedule
prg = lower_schedule_item(si)
File "/home/tiny/tinygrad/tinygrad/realize.py", line 22, in lower_schedule_item
return Device[si.out.device].get_runner(si.ast)
File "/home/tiny/tinygrad/tinygrad/device.py", line 330, in get_runner
def get_runner(self, ast:LazyOp) -> CompiledASTRunner: return self.to_program(self.get_linearizer(ast))
File "/home/tiny/tinygrad/tinygrad/device.py", line 301, in to_program
lib = self.compiler(src)
File "/home/tiny/tinygrad/tinygrad/runtime/ops_gpu.py", line 26, in compile_cl
raise RuntimeError(f"OpenCL Compile Error\n\n{ctypes.string_at(mstr, size=log_size.value).decode()}")
RuntimeError: OpenCL Compile Error
/tmp/comgr-bec8d2/input/CompileSource:18:70: error: casting to type 'half' is not allowed
*((__global float4*)(data0+alu2)) = (float4)(float4)((float)((half)(((val0).x*val3*(val6).x))),(float)((half)(((val0).y*val3*(val6).y))),(float)((half)(((val0).z*val3*(val6).z))),(float)((half)(((val0).w*val3*(val6).w))));
^~~~~~~~~~~~~~~~~~~~~~~~~~
/tmp/comgr-bec8d2/input/CompileSource:19:70: error: casting to type 'half' is not allowed
*((__global float4*)(data0+alu3)) = (float4)(float4)((float)((half)(((val1).x*val4*(val6).x))),(float)((half)(((val1).y*val4*(val6).y))),(float)((half)(((val1).z*val4*(val6).z))),(float)((half)(((val1).w*val4*(val6).w))));
^~~~~~~~~~~~~~~~~~~~~~~~~~
/tmp/comgr-bec8d2/input/CompileSource:20:70: error: casting to type 'half' is not allowed
*((__global float4*)(data0+alu4)) = (float4)(float4)((float)((half)(((val2).x*val5*(val6).x))),(float)((half)(((val2).y*val5*(val6).y))),(float)((half)(((val2).z*val5*(val6).z))),(float)((half)(((val2).w*val5*(val6).w))));
^~~~~~~~~~~~~~~~~~~~~~~~~~
3 errors generated.
Error: Failed to compile source (from CL or HIP source to LLVM IR).
|